
Составление robots.txt, проблемы индексации и примеры
При каждом обращении к сайту поисковые роботы первым делом ищут и считывают файл robots.txt. В нем записаны специальные директивы, управляющие поведением робота. Скрытую опасность для любого сайта может нести как отсутствие этого файла, так и его некорректная настройка. Предлагаю детальнее изучить вопрос настройки robots.txt вообще и для CMS WordPress в частности, а также обратить внимание на частые ошибки.
Файл robots.txt и стандарт исключений для роботов
Все поисковые системы понимают инструкции, написанные в специальном файле согласно стандарта исключений для роботов. В этих целях используется обычный текстовый файл с названием robots.txt, расположенный в корневом каталоге сайта. При корректном размещении содержимое этого файла можно посмотреть на любом сайте просто дописав после адреса домена /robots.txt. Например, http://site.site/robots.txt.
Инструкции для роботов позволяют запрещать к сканированию файлы/каталоги/страницы, ограничивать частоту доступа к сайту, указывать зеркало и XML карту. Каждую инструкцию пишут с новой строки в следующем формате:
[директива]: [значение]
Весь список директив разбивают на секции (записи), разделяя их одной или несколькими пустыми строками. Новую секцию начинают с одной или нескольких инструкций User-agent. Запись должна содержать как минимум одну директиву User-agent и одну Disallow.
Текст после символа # (решетка) считается комментарием и игнорируется поисковыми роботами.
Директива User-agent
User-agent — первая директива в секции, сообщает имена роботов, для которых предназначены следующие за ней правила. Звездочка в значении обозначает любое имя, разрешается только одна секция с инструкциями для всех роботов. Пример:
# инструкции для всех роботов
User-agent: *
…
# инструкции для роботов Яндекса
User-agent: Yandex
…
# инструкции для роботов Google
User-agent: Googlebot
…
Директива Disallow
Disallow — основная директива, запрещающая сканирование URL/файлов/каталогов, имена которых полностью или частично совпадают с указанными после двоеточия.
Продвинутые поисковые роботы вроде Яндекса и Google понимают спецсимвол * (звездочка), обозначающий любую последовательность символов. Подстановку не желательно использовать в секции для всех роботов.
Примеры директивы Disallow:
# пустое значение разрешает индексировать все
User-agent: *
Disallow:
# запрещает сканировать весь сайт
User-agent: *
Disallow: /
# запрещает к сканированию все файлы и/или каталоги, начинающиеся из символов ‘wp-‘
User-agent: *
Disallow: /wp-
# запрещает сканировать файлы page-1.php, page-vasya.php, page-news-345.php
# вместо * может встречаться любая последовательность символов
User-agent: *
Disallow: /page-*.php
Директива Allow (неофициальная)
Allow разрешает сканирование указанных ресурсов. Официально этой директивы нету в стандарте исключений для роботов, поэтому не желательно использовать ее в секции для всех роботов (User-agent: *). Отличный пример использования — разрешить к сканированию ресурсы из каталога, который ранее запрещен к индексации директивой Disallow:
# запрещает сканировать ресурсы начинающиеся с /catalog
# но разрешает сканировать страницу /catalog/page.html
User-agent: Yandex
Disallow: /catalog
Allow: /catalog/page.html
Sitemap (неофициальная)
Sitemap — директива, указывающая адрес карты сайта в формате XML. Эта директива так же не описана в стандарте исключений и поддерживается не всеми роботами (работает для Яндекс, Google, Ask, Bing и Yahoo). Можно указывать одну или несколько карт — все будут учтены. Может использоваться без User-agent после пустой строки.
Пример:
# одна или несколько карт в формате XML, указывается полный URL
Sitemap: http://sitename.com/sitemap.xml
Sitemap: http://sitename.com/sitemap-1.xml
Директива Host (только Яндекс)
Host — директива для робота Яндекс, указывающая основное зеркало сайта. Вопрос о зеркалах детальнее можно изучить в справке Яндекса. Эту инструкцию можно указывать как в секции для роботов Яндекса, так и отдельной записью без User-agent (инструкция межсекционная и в любом случае будет учтена Яндексом, а остальные роботы ее проигнорируют). Если в одном файле Host указан несколько раз, то будет учтена только первая. Примеры:
# указываем главное зеркало в секции для Яндекса
User-agent: Yandex
Disallow:
Host: sitename.com
# главное зеркало для сайта с SSL сертификатом
User-agent: Yandex
Disallow:
Host: https://sitename.com
# или отдельно без User-agent после пустой строки
Host: sitename.com
Другие директивы
Роботы Яндекса также понимают директивы Crawl-delay и Clean-param. Детальнее об их использовании читайте в справочной документации.
Роботы, директивы robots.txt и индекс поисковых систем
Ранее поисковые роботы следовали директивам robots.txt и не добавляли в индекс «запрещенных» там ресурсов.
Сегодня все обстоит иначе. Если Яндекс послушно исключит из индекса адреса, запрещенные в файле роботс, то Google поступит совершенно иначе. Он обязательно добавит их индекс, но в результатах поиска будет стоять надпись «Описание веб-страницы недоступно из-за ограничений в файле robots.txt».
Почему Google добавляет в индекс страницы, запрещенные в robots.txt?
Ответ кроется в маленькой хитрости гугла. Если внимательно прочесть справку для вебмастера, то все становится более чем понятно:
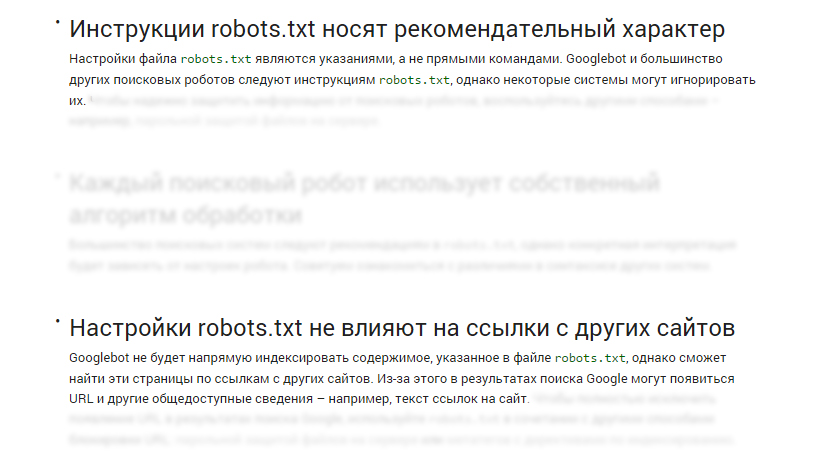
Google без зазрения совести сообщает, что директивы в robots.txt являются рекомендацией, а не прямыми командами к действию.
Это означает, что робот директивы учитывает, но поступает все-же по-своему. И он может добавить в индекс страницу, запрещенную в robots.txt, если встретит на нее ссылку.
Добавление адреса в robots.txt не гарантирует исключения его из индекса поисковой системы Google.
Индекс Google + некорректный robots.txt = ДУБЛИ
Практически каждое руководство в сети говорит о том, что закрытие страниц в robots.txt запрещает их индексацию.
Ранее так и было. Но мы уже знаем, что для Google такая схема сегодня не работает. А что еще хуже — каждый последовавший таким рекомендациям совершает огромную ошибку — закрытые URL попадают в индекс и помечаются как дубли, процент дублированного контента постоянно растет и рано или поздно сайт наказывается фильтром Панда.
Google предлагает два действительно рабочих варианта для исключения из индекса ресурсов веб-сайта:
- закрытие паролем (применяется для файлов вроде .doc, .pdf, .xls и других)
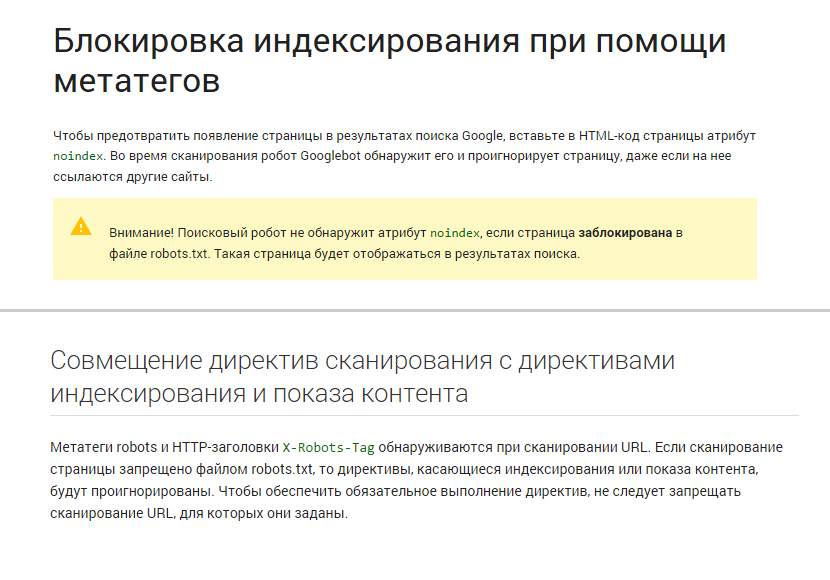
- добавление метатега robots с атрибутом noindex в(применяется для веб-страниц):
<meta name="robots" content="noindex, nofollow">
Главное, что нужно учесть:
Если на веб-страницу добавить указанный выше мета-тег, запрещающий индексацию, и дополнительно запретить сканирование этой-же страницы в robots.txt, то робот Google не сможет прочесть мета-тег с запретом и добавит страницу в индекс!
(поэтому он и пишет в результатах поиска, что описание ограничено в robots.txt)
Детальнее об этой проблеме можно почитать в справке Google. А решение здесь одно — открывать доступ в robots.txt и настраивать запрет на индексацию страниц метатегом (или паролем, если речь о файлах).
Примеры robots.txt для WordPress
Если внимательно ознакомиться с предыдущим разделом, то становится понятно, что сегодня не стоит практиковать чрезмерный запрет адресов в robots.txt, по крайне мере для Google. Управлять индексацией страниц лучше через метатег robots.
Вот самый банальный и при этом совершенно правильный robots.txt для WordPress:
User-agent: *
Disallow:
Host: sitename.com
Удивлены? Еще бы! Все гениальное просто ? На западных ресурсах, где нету Яндекса, рекомендации по составлению robots.txt для WordPress сводятся к двум первым строчкам, как это показали авторы WordPress SEO by Yoast.
Правильно настроенный SEO-плагин позаботится о канонических ссылках и метатеге robots со значением noindex, а страницы админки под паролем и не нуждаются в запрете индексации (исключением могут быть только страницы входа и регистрации на сайта — убедитесь, что на них есть meta тег robots со значением noindex). Карту сайта правильнее добавить вручную в вебмастере поисковой системы и заодно проследить, чтобы она была корректно прочитана. Осталось единственное и важное для рунета — указать главное зеркало для Яндекса.
Еще один вариант, подойдет для менее смелых:
User-agent: *
Disallow: /wp-admin
Host: sitename.com
Sitemap: http://sitename.com/sitemam.xml
В первой секции запрещается индексация для всех роботов каталога wp-admin и его содержимого. В последних двух строках указанные зеркало сайта для робота Яндекса и карта сайта.
Прежде чем изменять свой robots.txt…
Если приняли решение о смене директив в robots.txt, то сначала позаботьтесь о трех вещах:
- Убедитесь, что в корне вашего сайта нету дополнительных файлов или каталогов, содержимое которых стоит скрыть от сканирования (это могут быть личные файлы или медиаресурсы);
- Включите канонические ссылки в своем SEO-плагине (это исключит из индекса URL c параметрами запроса вроде http://sitename.com/index.php?s=word)
- Настройте вывод метатега robots со значением noindex на страницах, которые хотите скрыть от индексации (для WordPress это архивы по дате, метке, автору и страницы пагинации). Сделать это можно для части страниц в настройках SEO-плагинов (в All In One SEO неполные настройки). Или специальным кодом вывести самостоятельно:
/* ==========================================================================
* Добавляем свой
* ========================================================================== */
function my_meta_noindex () {
if (
//is_archive() OR // любые страницы архивов — за месяц, за год, по рубрике, по авторам
//is_category() OR // архивы рубрик
is_author() OR // архивы статей по авторам
is_time() OR // архивы статей по времени
is_date() OR // архивы статей по любым датам
is_day() OR // архивы статей по дням
is_month() OR // архивы статей по месяцам
is_year() OR // архивы статей по годам
is_tag() OR // архивы статей по тегам
is_tax() OR // архивы статей для пользовательской таксономии
is_post_type_archive() OR // архивы для пользовательского типа записи
//is_front_page() OR // статическая главная страница
//is_home() OR // главная страница блога с последними записями
//is_singular() OR // любые типы записей — одиночные посты, страницы, вложения и т.д.
//is_single() OR // любой одиночный пост любого типа постов (кроме вложений и Страниц)
//is_page() OR // любая одиночная Страница («Страницы» в админке)
is_attachment() OR // любая страница вложения
is_paged() OR // все и любые страницы пагинации
is_search() // страницы результатов поиска по сайту
) {
echo «».».»\n»;
}
}
add_action(‘wp_head’, ‘my_meta_noindex’, 3);
/* ========================================================================== */
В строчках, начинающихся с // метатег не будет выводится (в каждой строке описано для какой страницы предназначено правило). Добавляя или удаляя в начале строки два слеша, можно контролировать будет ли выводиться мета-тег роботс или нет на определенной группе страниц.
В двух словах о том, что закрывать в robots.txt
С настройкой файла роботс и индексацией страниц нужно запомнить два важных момента, которые ставят все на свои места:
Используйте файл robots.txt, чтобы управлять доступом к файлам и каталогам сервера. Файл robots.txt играет роль электронного знака «Вход запрещен: частная территория»
Используйте метатег robots, чтобы содержание не появлялось в результатах поиска. Если на странице есть метатег robots с атрибутом noindex, большинство роботов исключает всю страницу из результатов поиска, даже если на нее ссылаются другие страницы.